进阶篇
2.1.1. 扩容后预估容量
假设现在有一个长度为 2 的切片,对其进行扩容,增加三个元素
sli := []int{1,2}
sli = append(sli, 3, 4, 5)对于扩容后的切片,长度为 5,这一点没有任何争议。
但容量呢?难道也是 5?
经过运行验证,实际的容量为 6 。
什么情况?这 6 是如何计算出来的呢?
这就不得不去 Go 源代码中一探究竟,在 runtime/slice.go 关于 slice 扩容增长的代码如下:
newcap := old.cap
if newcap+newcap < cap {
newcap = cap
} else {
for {
if old.len < 1024 {
newcap += newcap
} else {
newcap += newcap / 4
}
if newcap >= cap {
break
}
}
}对于这段代码,只要理解前两行,其他的就不攻自破了
- 第一行的 old.cap:扩容前的容量,对于此例,就是 2
- 第二行的 cap:扩容前容量加上扩容的元素数量,对于此例,就是 2+3
整段代码的核心就是要计算出扩容后的预估容量,也就是 newcap,计算的具体逻辑是:
- 若 old.cap * 2 小于 cap,那 newcap 就取大的 cap
- 若 old.cap * 2 大于 cap,并且old.cap 小于 1024,那 newcap 还是取大,也即 newcap = old.cap * 2
- 若 old.cap * 2 大于 cap,但是old.cap 大于 1024,那两倍冗余可能就有点大了,系数换成 1.25,也即 newcap = old.cap * 1.25
但 newcap 只是预估容量,并不是最终的容量,要计算最终的容量,还需要参考另一个维度,也就是内存分配。
2.1.2 内存的分配规律
举个现实中的例子来说
你家里有五个人,每个人都想吃绿豆糕,因此你的需求就是 5,对应上例中的 cap ,于是你就到超市里去买。
但超市并不是你家开的,绿豆糕都是整盒整盒的卖,没有卖散的,每盒的数量是 6 个,因此你最少买 6 个。
每次购买的最少数量,就可以类比做 Go 的内存分配规律。
只有了解了 Go 的内存分配规律,我们才能准确的计算出我们最少得买多少的绿豆糕(得申请多少的内存,分配多少的容量)。
关于内存管理模块的代码,在 runtime/sizeclasses.go
// class bytes/obj bytes/span objects tail waste max waste
// 1 8 8192 1024 0 87.50%
// 2 16 8192 512 0 43.75%
// 3 32 8192 256 0 46.88%
// 4 48 8192 170 32 31.52%
...
// 17 256 8192 32 0 5.86%
// 18 288 8192 28 128 12.16%
// 19 320 8192 25 192 11.80%
// 20 352 8192 23 96 9.88%
// 21 384 8192 21 128 9.51%
// 22 416 8192 19 288 10.71%
// 23 448 8192 18 128 8.37%
// 24 480 8192 17 32 6.82%
// 25 512 8192 16 0 6.05%
...
// 66 32768 32768 1 0 12.50%从上面这个表格中,可以总结出一些规律。
- 在小于16字节时,每次以8个字节增加
- 当大于16小于2^8时,每次以16字节增加
- 当大于28小于29时以32字节增加
- 依此规律…
2.1.3. 匹配到合适的内存
第一节中我们例子中,主人公是一个元素类型为 int 的切片,每个 int 占用为 8 个字节,由于我们计算出的 newcap 为 5,因此新的切片,最少最少要占用 5*8 = 40 个字节。
再到第二节中的表格中查看,发现离 40 byte 最接近的是 32 和 48 两个档位。
如果是 32 byte,就是不够用了,
因此 只能选择 48 这个档位去分配内存。
有了实际分配的内存,再反回去计算容量,就是扩容后真实的切片容量,也就是 48/8 = 6
2.2 goroutine 存在的意义是什么?
线程其实分两种:
- 一种是传统意义的操作系统线程
- 一种是编程语言实现的用户态线程,也称为协程,在 Go 中就是 goroutine
因此,goroutine 的存在必然是为了换个方式解决操作系统线程的一些弊端 -- 太重 。
太重表现在如下几个方面:
第一:创建和切换太重
操作系统线程的创建和切换都需要进入内核,而进入内核所消耗的性能代价比较高,开销较大;
第二:内存使用太重
一方面,为了尽量避免极端情况下操作系统线程栈的溢出,内核在创建操作系统线程时默认会为其分配一个较大的栈内存(虚拟地址空间,内核并不会一开始就分配这么多的物理内存),然而在绝大多数情况下,系统线程远远用不了这么多内存,这导致了浪费;
另一方面,栈内存空间一旦创建和初始化完成之后其大小就不能再有变化,这决定了在某些特殊场景下系统线程栈还是有溢出的风险。
相对的,用户态的goroutine则轻量得多:
- goroutine是用户态线程,其创建和切换都在用户代码中完成而无需进入操作系统内核,所以其开销要远远小于系统线程的创建和切换;
- goroutine启动时默认栈大小只有2k,这在多数情况下已经够用了,即使不够用,goroutine的栈也会自动扩大,同时,如果栈太大了过于浪费它还能自动收缩,这样既没有栈溢出的风险,也不会造成栈内存空间的大量浪费。
2.3 说说 Go 中闭包的底层原理?
1. 什么是闭包?
一个函数内引用了外部的局部变量,这种现象,就称之为闭包。
例如下面的这段代码中,adder 函数返回了一个匿名函数,而该匿名函数中引用了 adder 函数中的局部变量 sum ,那这个函数就是一个闭包。
package main
import "fmt"
func adder() func(int) int {
sum := 0
return func(x int) int {
sum += x
return sum
}
}而这个闭包中引用的外部局部变量并不会随着 adder 函数的返回而被从栈上销毁。
我们尝试着调用这个函数,发现每一次调用,sum 的值都会保留在 闭包函数中以待使用。
func main() {
valueFunc:= adder()
fmt.Println(valueFunc(2)) // output: 2
fmt.Println(valueFunc(2)) // output: 4
}2. 复杂的闭包场景
写一个闭包是比较容易的事,但单单会写简单的闭包函数,还远远不够,如果不搞清楚闭包真正的原理,那很容易在一些复杂的闭包场景中对函数的执行逻辑进行误判。
别的不说,就拿下来这个例子来说吧?
你觉得它会打印什么呢?
是 6 还是 11 呢?
import "fmt"
func func1() (i int) {
i = 10
defer func() {
i += 1
}()
return 5
}
func main() {
closure := func1()
fmt.Println(closure)
}3. 闭包的底层原理?
还是以最上面的例子来分析
package main
import "fmt"
func adder() func(int) int {
sum := 0
return func(x int) int {
sum += x
return sum
}
}
func main() {
valueFunc:= adder()
fmt.Println(valueFunc(2)) // output: 2
}我们先对它进行逃逸分析,很容易发现 sum 作为 adder 函数局部变量,并不是分配在栈上,而是分配在堆上的。
这就解决了第一个疑惑:为什么 adder 函数返回后, sum 不会随之销毁?
$ go build -gcflags="-m -m -l" demo.go
# command-line-arguments
./demo.go:8:3: adder.func1 capturing by ref: sum (addr=true assign=true width=8)
./demo.go:7:9: func literal escapes to heap:
./demo.go:7:9: flow: ~r0 = &{storage for func literal}:
./demo.go:7:9: from func literal (spill) at ./demo.go:7:9
./demo.go:7:9: from return func literal (return) at ./demo.go:7:2
./demo.go:6:2: sum escapes to heap:
./demo.go:6:2: flow: {storage for func literal} = &sum:
./demo.go:6:2: from func literal (captured by a closure) at ./demo.go:7:9
./demo.go:6:2: from sum (reference) at ./demo.go:8:3
./demo.go:6:2: moved to heap: sum
./demo.go:7:9: func literal escapes to heap
./demo.go:15:23: valueFunc(2) escapes to heap:
./demo.go:15:23: flow: {storage for ... argument} = &{storage for valueFunc(2)}:
./demo.go:15:23: from valueFunc(2) (spill) at ./demo.go:15:23
./demo.go:15:23: flow: {heap} = {storage for ... argument}:
./demo.go:15:23: from ... argument (spill) at ./demo.go:15:13
./demo.go:15:23: from fmt.Println(valueFunc(2)) (call parameter) at ./demo.go:15:13
./demo.go:15:13: ... argument does not escape
./demo.go:15:23: valueFunc(2) escapes to heap可另一个问题,又浮现出来了,就算它不会销毁,那闭包函数若是存储的若是 sum 拷贝后的值,那每次调用闭包函数,里面的 sum 应该都是一样的,调用两次都应该返回 2,而不是可以累加记录。
因此,可以大胆猜测,闭包函数的结构体里存储的是 sum 的指针。
为了验证这一猜想,只能上汇编了。
通过执行下面的命令,可以输出对应的汇编代码
go build -gcflags="-S" demo.go输出的内容相当之多,我提取出下面最关键的一行代码,它定义了闭包函数的结构体。
其中 F 是函数的指针,但这不是重点,重点是 sum 存储的确实是指针,验证了我们的猜。
type.noalg.struct { F uintptr; "".sum *int }(SB), CX4. 迷题揭晓
有了上面第三节的背景知识,那对于第二节给出的这道题,想必你也有答案了。
首先,由于 i 在函数定义的返回值上声明,因此根据 go 的 caller-save 模式, i 变量会存储在 main 函数的栈空间。
然后,func1 的 return 重新把 5 赋值给了 i ,此时 i = 5
由于闭包函数存储了这个变量 i 的指针。
因此最后,在 defer 中对 i 进行自增,是直接更新到 i 的指针上,此时 i = 5+1,所以最终打印出来的结果是 6
import "fmt"
func func1() (i int) {
i = 10
defer func() {
i += 1
}()
return 5
}
func main() {
closure := func1()
fmt.Println(closure)
}5. 再度变题
上面那题听懂了的话,再来看看下面这道题。
func1 的返回值我们不写变量名 i 了,然后原先返回具体字面量,现在改成变量 i ,就是这两小小小的改动,会导致运行结果大大不同,你可以思考一下结果。
import "fmt"
func func1() (int) {
i := 10
defer func() {
i += 1
}()
return i
}
func main() {
closure := func1()
fmt.Println(closure)
}如果你在返回值里写了变量名,那么该变量会存储 main 的栈空间里,而如果你不写,那 i 只能存储在 func1 的栈空间里,与此同时,return 的值,不会作用于原变量 i 上,而是会存储在该函数在另一块栈内存里。
因此你在 defer 中对原 i 进行自增,并不会作用到 func1 的返回值上。
所以打印的结果,只能是 10。
你答对了吗?
6. 最后一个问题
不知道你有没有发现,在第一节示例中的 sum 是存储在堆内存中的,而后面几个示例都是存储在栈内存里。
这是为什么呢?
仔细对比,不难发现,示例一返回的是闭包函数,闭包函数在 adder 返回后还要在其他地方继续使用,在这种情况下,为了保证闭包函数的正常运行,无论闭包函数在哪里,i 都不能回收,所以 Go 编译器会智能地将其分配在堆上。
而后面的其他示例,都只是涉及了闭包的特性,并不是直接把闭包函数返回,因此完全可以将其分配在栈上,非常的合理。
7. 总结一下
- 闭包函数里引用的外部变量,是在堆还是栈内存申请的,取决于,你这个闭包函数在函数 Return 后是否还会在其他地方使用,若会, 就会在堆上申请,若不会,就在栈上申请。
- 闭包函数里,引用的外部变量,存储的并不是对值的拷贝,存的是值的指针。
- 函数的返回值里若写了变量名,则该变量是在上级的栈内存里申请的,return 的值,会直接赋值给该变量。
2.4 defer 的变量快照什么情况会失效?
关于 defer 的基本知识点,我在以前的教程中有写过:流程控制:defer 延迟语句
其中有一个知识是 defer 的变量快照,举个简单的例子来说
在下面这段代码中,会先打印出来 18,即使后面 age 已经被改变了,可 defer 中的 age还是 修改之前的 0,这种现象称之为变量快照。
func func1() {
age := 0
defer fmt.Println(age) // output: 0
age = 18
fmt.Println(age) // output: 18
}
func main() {
func1()
}对于这个输出结果,相信还是挺容易理解的。
接下来,我请大家再看下面这个例子,可以猜猜看会输出什么?
func func1() {
age := 0
defer func() {
fmt.Println(age)
}()
age = 18
return
}
func main() {
func1()
}正确的答案是:18, 而不是 0
你肯定会纳闷:不对啊,defer 不是会对变量的值做一个快照吗?答案应该是 0 啊,为什么会是 18?
实际上,仔细观察,可以发现上面的两个例子的区别就在于,一个 defer 后接的是单个表达式,另一个 defer 后接的是一个函数,并且不是普通函数,而是一个匿名的闭包函数。
根据闭包的特性,实际上在闭包函数存的是 age 这个变量的指针(原因可以查看上一篇文章:Go 语言面试题 100 讲之 014篇:说说 Go 中闭包的底层原理?),因而,在 defer 后所修改的值会直接影响到 defer 中的 age 的值。
总结一下:
- 若 defer 后接的是单行表达式,那defer 中的 age 只是拷贝了
func1函数栈中 defer 之前的 age 的值; - 若 defer 后接的是闭包函数,那defer 中的 age 只是存储的是
func1函数栈中 age 的指针。
2.5 说说你对 Go 里的抢占式调度的理解
Go 从 v1.1 发现展到目前的 v1.16,协程调度策略也在不断的完善优化。
下面我将从 v.1.1 开始讲讲 协程调度策略中抢占式调度的发展历程。
v1.1 的非抢占式调用
在最初的 v1.1 版本中,只有当一个协程主动让出 CPU 资源(可以是运行结束,也可以是发生了系统调用或其他阻塞性操作),才能触发调度,进行下一个协程。
而如果一个协程运行了很久,也没有主动让出的动作发生,就会自私的一个人占用整个线程,该线程无法再去运行其他的 goroutine 了。
这种策略会让 Go 的并发性大打折扣,名不符实。
v1.2 基于协作的抢占式调用
由于 v1.1 的非抢占式调用,以程序的并发效率影响实在太大。因为在下一个版本 v1.2 就紧急地对调度策略进行了临时的优化。经过优化后,go 从 v1.2 开始支持抢占式的调用:
- 如果 sysmon 监控线程发现有个协程 A 执行之间太长了(或者 gc 场景,或者 stw 场景),那么会友好的在这个 A 协程的某个字段设置一个抢占标记 ;
- 协程 A 在 call 一个函数的时候,会复用到扩容栈(morestack)的部分逻辑,检查到抢占标记之后,让出 cpu,切到调度主协程里;
之所以说 v1.2 的抢占式调用是临时的优化方案,是因为这种抢占式调度是基于协作的。在一些的边缘场景下,协程还是在会独自占用整个线程无法让出。
从上面的流程中,你应该可以注意到,A 调度权被抢占有个前提:A 必须主动 call 函数,这样才能有走到 morestack 的机会。
反面案例可以看下面这个程序,当运行到 time.Sleep 后,线程上的 goroutine 会从 main 切换到前面的匿名函数协程,而这个匿名函数协程并是在作for 死循环,并没有任何可以让出 cpu 运行权的操作,因为该程序在 go 1.14 之前的 go版本中,运行后会一直卡住,而不会打印 I got scheduled!
package main
import (
"fmt"
"runtime"
"time"
)
func main() {
runtime.GOMAXPROCS(1)
fmt.Println("The program starts ...")
go func() {
for {
}
}()
time.Sleep(time.Second)
fmt.Println("I got scheduled!")
}v1.14 基于信号的抢占式调用
基于协作的抢占式调用,伴随着 Go 走过了12个版本,终于在 v1.14 迎来了真正的抢占式调用。
为什么说是真正的抢占式调用呢?
因为 v1.14 的这种抢占式调用是基于信号的,不管你的协程有没有意愿主动让出 cpu 运行权,只要你这个协程超过某个时间,就会发送信号强行夺取 cpu 运行权。
那么这个时间具体是多少呢? 20ms
延伸阅读
2.6 简述一下 Go 栈空间的扩容/缩容过程?
扩容流程
为啥会有栈空间扩容
由于当前的 Go 的栈结构使用的是连续栈,并且初始值才 2k 比较小,因此随着函数的调用层级加深,Go 的初始栈空间就可能不够用,不够用的话,就会触发栈空间的扩容。
栈空间扩容啥时会触发
编译器会为函数调用插入运行时检查runtime.morestack,它会在几乎所有的函数调用之前检查当前goroutine 的栈内存是否充足,如果当前栈需要扩容,会调用runtime.newstack 创建新的栈。
而新的栈空间,是旧栈空间大小(通过保存在goroutine中的stack信息里记录的栈区内存边界计算出来的)的两倍,但最大栈空间大小不能超过 maxstacksize ,也就是 1G。
缩容流程
为啥会有栈空间缩容
在函数返回后,对应的栈空间会回收,如果调用栈比较深,那么随着函数一个一个返回,回收的栈空间会越来越多。假设在调用栈最深的时候,整体的栈空间扩容到了 100M,那么随着函数的返回,到某一个函数的时候,100M 的栈空间只有 1M 是实际占用的,内存利用率只有区区的 1% ,实在太浪费了。
栈空间缩容啥时会触发
因此在垃圾回收的时候,有必要检查一下栈空间里内存利用率,当利用率低于 25% 时,就要开始进行缩容,缩容成原来的栈空间的 50%,但同时也不能小于栈空间的原始值即最小值,2KB。
相同点
不管是扩容还是缩容,都是使用 runtime.copystack 函数来开辟新的栈空间,然后将旧栈的数据全部拷贝至新的栈空间,并调整原来指针的指向。
延伸阅读
2.7 说一下 GMP 模型的原理
1. 什么是 GMP ?
G:Goroutine,也就是 go 里的协程,是用户态的轻量级线程,具体可以创建多个 goroutine ,取决你的内存有多大,一个 goroutine 大概需要 4k 内存,只要你不是在 32 位的机器上,那么创建个几百万个的 goroutine 应该没有问题。M:Thread,也就是操作系统线程,go runtime 最多允许创建 10000 个操作系统线程,超过了就会抛出异常P:Processor,处理器,数量默认等于开机器的cpu核心数,若想调小,可以通过 GOMAXPROCS 这个环境变量设置。
2. GMP 核心
两个队列
在整个 Go 调度器的生命周期中,存在着两个非常重要的队列:
- 全局队列(Global Queue):全局只有一个
- 本地队列(Local Queue):每个 P 都会维护一个本地队列
当你执行 go func() 创建一个 goroutine 时,会优选将该协程放入到当前 P 的本地队列中等待被 P 选中执行。
但若当前 P 的本地队列任务太多了,已经存放不下了,那么这个 goroutine 就只能放入到全局队列中。
两种调度
一个协程得以运行,需要同时满足以下两个条件:
- P 已经和某个线程进行绑定,这样才能参与操作系统的调度获得 CPU 时间
- P 已经从队列中(可以是本地队列,也可以是全局队列,甚至是从其他 P 的队列)取到该协程
第一个条件就是 操作系统调度,而第二个其实就是 Go 里的调度器。
操作系统调度
假设一台机器上有两个 CPU 核心,意味着,同时在同一时间里,只能有两个线程运行着。
可如果该机器上实际开启了 4 个线程,要是先执行一个线程完再执行另一个线程,那么当某一个线程因为一些阻塞性的系统调用而阻塞时,CPU 的时间就会因此而白白浪费掉了。
更合适的做法是,使用 操作系统调度策略,设定一个调度周期,假设是 10ms (毫秒),那在一个周期里,每个线程都平均分,都只能得到 2.5ms 的CPU 运行时间。
可如果机器上有 1000 个线程呢?难道每个线程都分个 0.01 ms (也就是 10 微秒)吗?
要知道,CPU 从 A 线程切换到 B 线程,是有巨大的时间浪费在线程上下文的切换,如果切换得太频繁,就会有大量的 CPU 时间白白浪费。
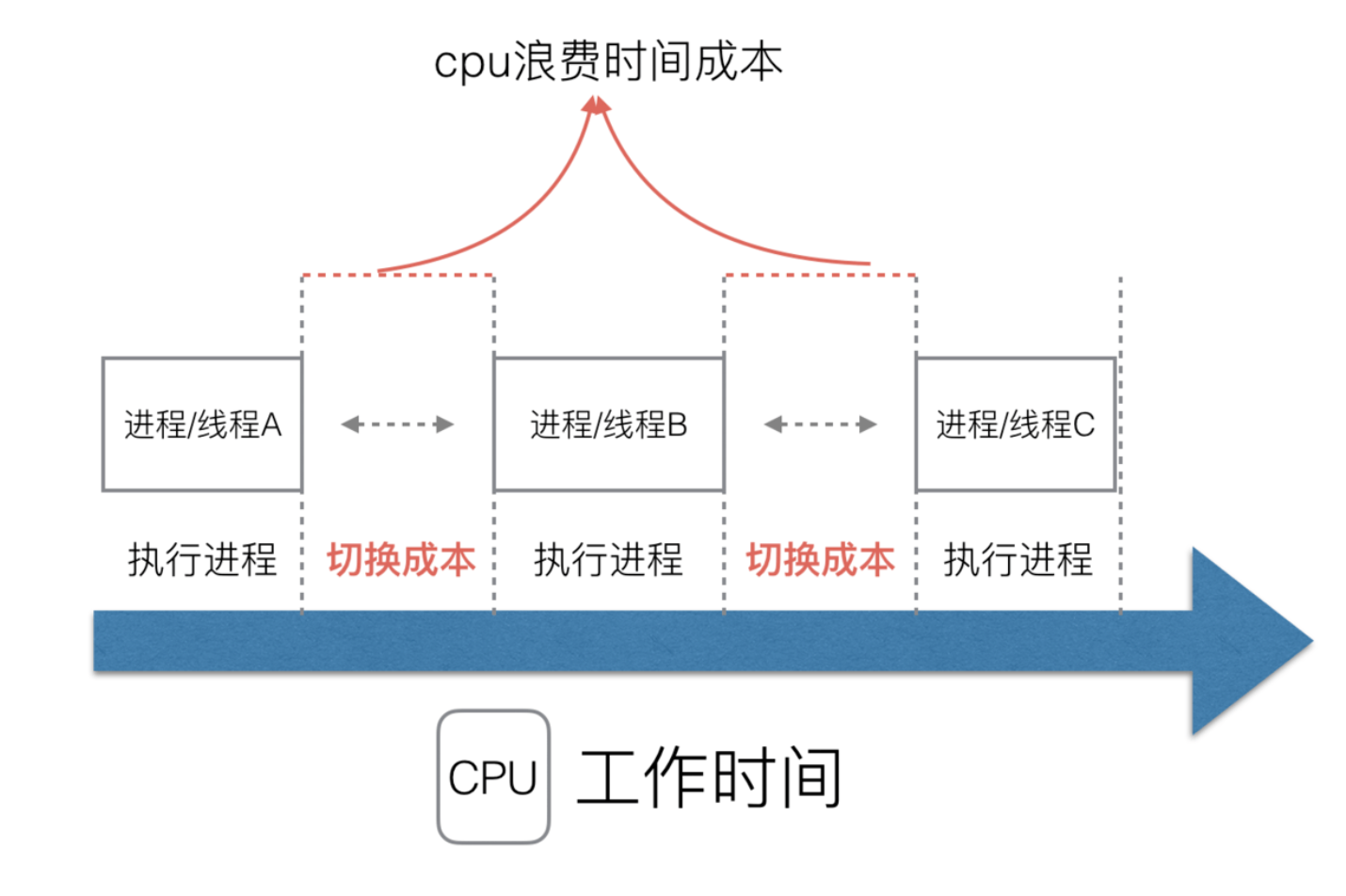
因此,通常会限制最小的时间片的长度,假设为 2ms,受此调整,现在调度周期就会变成 2*1000 = 2s 。
Go调度器
在 Go 中需要用到调度的,无非是如下几种:
**将 P 绑定到一个合适的 M **
P 本身不能直接运行 G,只将 P 跟 M 绑定后,才能执行 G。
假设 P1 当前正绑定在 M1 上运行 G1,此时 G1 内部发生了一次系统调度后,P1 就会与 M1 进行解绑,然后再从空闲的线程队列中再寻找一个来绑定,假设绑定的是 M2,可如果没有空闲的线程呢?那没办法,只能创建一个新的线程再进行绑定。
绑定后,就会再从本地的队列中寻找 G 来执行(如果没找到,就会去其他队列找,上面已经讲过,不再赘述)。
过了一段时间后,之前 M1 上 G1 发生的系统调用结束后,M1 会去找原先自己的搭档 P1(它自己会记录),如果自己的老搭档也刚好空闲着,就可以再次合作进行绑定,接着运行 G1 未完成的工作。
可不幸的是,P1 已经找到了新的合作伙伴 M2,暂时没空搭理 M1 。
M1 联系不上 P1,只能去寻找有没有其他空闲的 P ,如果所有的 P 都被绑定着,说明现在任务非常繁重,想完成任务只能排队慢慢等。
于是,M1 上的 G1 就会被标记为 Runable ,放到全局队列中,而 M1 自身也会因为没有 P 可以绑定而进入休眠状态,如果长时间休眠等待 则会 GC 回收销毁
为 P 选中一个 G 来执行
P 就像是一个流水线工人,而 P 的本地队列就是流水线,G 是流水线上的零件。而 Go 调度器就是流水线组长,负责监督工人的是不是有在努力的工作。
完成一个 G 后,P 就得立马接着从队列中拿到下一个 G,继续干活。
遇到手脚麻利的 P ,干完了自己的活,本想着可以偷懒一会,没想到却被组长发现了,立马就从全局队列中拿了些新的 G 交到 P 的手里。
天真的 P 以为只要把 全局队列中的 G 的也干完了,就肯定 能休息了吧?
当 P 又快手快脚的把全局队列中的 G 也都干完的时候,P 非常得意,心想:终于可以休息会了。
没想到又被眼尖的组长察觉到了:不错啊,小 P,手脚挺麻利的。看看其他人,还那么多活没干完。真是拖后腿。可谁让咱是一个团队的呢,要有集体荣誉感,你能者多劳。
说完,就把其他人的 G 放到了我的工作上。。。
3. 调度器的设计策略
复用线程
避免频繁的创建、销毁线程,而是对线程的复用。
1)work stealing 机制
当本线程无可运行的 G 时,尝试从其他线程绑定的 P 偷取 G,而不是销毁线程。
2)hand off 机制
当本线程因为 G 进行系统调用阻塞时,线程释放绑定的 P,把 P 转移给其他空闲的线程执行。
利用并行
GOMAXPROCS 设置 P 的数量,最多有 GOMAXPROCS 个线程分布在多个 CPU 上同时运行。GOMAXPROCS 也限制了并发的程度,比如 GOMAXPROCS = 核数/2,则最多利用了一半的 CPU 核进行并行。
抢占调度
在 Go 中,一个 goroutine 最多占用 CPU 10ms,防止其他 goroutine 被饿死,这是协作式抢占调度。
而在 go 1.14+ ,Go 开始支持基于信号的真抢占调度了。
全局 G 队列
在新的调度器中依然有全局 G 队列,但功能已经被弱化了,当 M 执行 work stealing 从其他 P 偷不到 G 时,它可以从全局 G 队列获取 G。
延伸阅读
2.8 GMP 模型为什么要有 P ?
GM 模型是怎样的?
在 Go v1.1 之前,实际上 GMP确实是没有 P 的,所有的 M 线程都要从 全局队列中获取 G 来执行任务,为了避免冲突,从全局队列中获取 G 的时候,要先获取一把大锁。
当一个程序的并发量比较小的时候,影响还不大,而当程序的并发量非常大的时候,这个全局队列会成为性能的瓶颈。
除此之外 ,若直接把 G 从全局队列分配给 M,那么当 G 中当生系统调用或者其他阻塞性的操作时,M 会有一段时间处于挂起的状态,此时又没有新创建线程的线程来代替该线程继续从队列中取出其他 G 来运行,从效率上其实会打折扣。
P 带来的改变
加了 P 之后会带来什么改变呢?
- 每个 P 有自己的本地队列,大幅度的减轻了对全局队列的直接依赖,所带来的效果就是锁竞争的减少。而 GM 模型的性能开销大头就是锁竞争。
- 当一个 M 中 运行的 G 发生阻塞性操作时,P 会重新选择一个 M,若没有 M 就新创建一个 M 来继续从 P 本地队列中取 G 来执行,提高运行效率。
- 每个 P 相对的平衡上,在 GMP 模型中也实现了 Work Stealing 算法,如果 P 的本地队列为空,则会从全局队列或其他 P 的本地队列中窃取可运行的 G 来运行,减少空转,提高了资源利用率。
2.9 不分配内存的指针类型能用吗?
下面这个例子,先定义了一个类型为 *int 的指针类型,可是然后把 10 赋值给指针指向的值
package main
import (
"fmt"
)
func main() {
var i *int
*i=10
fmt.Println(*i)
}看起来好像没有啥问题,可为什么会报错呢?
$ go run demo.go
panic: runtime error: invalid memory address or nil pointer dereference
[signal SIGSEGV: segmentation violation code=0x1 addr=0x0 pc=0x109cea3]
goroutine 1 [running]:
main.main()
/Users/MING/Code/Golang/src/demo/demo.go:9 +0x23
exit status 2原因是我们只声明了指针类型,但并没有为其分配内存,没有内存地址,你赋给它的值应该存在哪里呢?自然只能报错了。
正确的写法应该是这样,在赋值给,先使用 new 函数给 i 分配内存。
package main
import (
"fmt"
)
func main() {
var i *int
i = new(int)
*i=10
fmt.Println(*i)
}2.10 如何让在强制转换类型时不发生内存拷贝?
当你使用要对一个变量从一个类型强制转换成另一个类型,其实都会发生内存的拷贝,而这种拷贝会对性能有所影响的,因此如果可以在转换的时候避免内存的拷贝就好了。
庆幸的是,在一些特定的类型下,这种想法确实是可以实现的。
比如将字符串转成 []byte 类型。
正常的转换方法是
// string to []byte
s1 := "hello"
b := []byte(s1)
// []byte to string
s2 := string(b)具体的代码如下
func main() {
msg1 :="hello"
sh := *(*reflect.StringHeader)(unsafe.Pointer(&msg1))
bh := reflect.SliceHeader{
Data: sh.Data,
Len: sh.Len,
Cap: sh.Len,
}
msg2 := *(*[]byte)(unsafe.Pointer(&bh))
fmt.Printf("%v", msg2)
}这段代码是不是看着有点晕啊,各种奇奇怪怪的写法,见都没见过。
其实核心知识点有三个:
- 一种定义变量的怪异方法
- 字符串的底层数据结构
- 切片的底层数据结构
正常我们所熟知的变量的声明定义方法是下面两种吧
// 第一种
var name string = "Go编程时光"
// 第二种
name := "Go编程时光"但还有一种方法,可能新手不知道,这种方法,我在之前的文章有提到过 详细图解:静态类型与动态类型
还是用上面的等价例子,它还可以这么写
name := (string)("Go编程时光")再回过头来理解最上面那段怪异的代码
- 第一个括号:肯定是某个类型对应的指针类型
- 第二个括号:就是第一个括号里类型对应的值
tmp := *(*reflect.StringHeader)(unsafe.Pointer(&msg))由于第一个括号里是个指针类型,那么第二个括号里肯定要是指针的值。
而通过 unsafe.Pointer 就可以将 &msg 指针的内存地址取出来。
两个括号合起来就是,声明并定义了一个 *reflect.StringHeader 类型的指针变量,对应的指针值还是原来 msg1 的内存地址。
那最前面的的那个那个 * ,大家应该都知道,是从*reflect.StringHeader 类型的指针变量中取出值。
那么你肯定要问了,int 和 bool、string 这些类型我都知道啊,这个reflect.StringHeader 是什么类型??没见过啊
其实他就是字符串的底层结构,是字符串最原始的样子。
type StringHeader struct {
Data uintptr
Len int
}同样的, SliceHeader 则是切片的底层数据结构
type SliceHeader struct {
Data uintptr
Len int
Cap int
}是不是觉得他们很像?
对咯,只要把 StringHeader 里的 Data 塞给 SliceHeader 里的 Data,再把 SliceHeader 里的 Len 塞给 SliceHeader 里的 Len 和 Cap ,就多费任何的空间创造出一个新的变量。
bh := reflect.SliceHeader{
Data: sh.Data,
Len: sh.Len,
Cap: sh.Len,
}最后再把 SliceHeader 通过上面的强制转换方法,再转成 []byte 就可以了,中间就不会有任何的内存拷贝的过程。
是不是真的有效果呢?来测试一下性能便知
先准备 demo.go
package mainimport ( "reflect" "unsafe")func String2Bytes(s string) []byte { sh := (*reflect.StringHeader)(unsafe.Pointer(&s)) bh := reflect.SliceHeader{ Data: sh.Data, Len: sh.Len, Cap: sh.Len, } return *(*[]byte)(unsafe.Pointer(&bh))}再准备 demo_test.go
package mainimport ( "bytes" "testing")func TestString2Bytes(t *testing.T) { x := "Hello Gopher!" y := String2Bytes(x) z := []byte(x) if !bytes.Equal(y, z) { t.Fail() }}// 测试标准转换[]byte性能func Benchmark_NormalString2Bytes(b *testing.B) { x := "Hello Gopher! Hello Gopher! Hello Gopher!" for i := 0; i < b.N; i++ { _ = []byte(x) }}// 测试强转换string到[]byte性能func Benchmark_String2Bytes(b *testing.B) { x := "Hello Gopher! Hello Gopher! Hello Gopher!" for i := 0; i < b.N; i++ { _ = String2Bytes(x) }}并在当前目录下执行
go mod init最后就可以执行如下命令进行测试,从输出的结果来看使用我们的黑魔法转换的效率要比普通的方法快太多了
$ go test -bench="." -benchmem goos: darwingoarch: amd64pkg: demoBenchmark_NormalString2Bytes-8 36596674 28.5 ns/op 48 B/op 1 allocs/opBenchmark_String2Bytes-8 1000000000 0.253 ns/op 0 B/op 0 allocs/op延伸阅读
- [Golang中[]byte与string转换全解析](
2.11 Go 中的 GC 演变是怎样的?
标记清除法
在 Go v1.3 之前采用的是 标记-清除(mark and sweep)算法。
它的逻辑是,先将整个程序挂起(STW, stop the world),然后遍历程序中的对象,只要是可达的对象,都会被标记保留(红色),而那些不可达的对象(白色),则会被清理掉,清理完成后,会恢复程序。然后不断重复该过程。

这种标记-清除的算法,会有一段 STW 的时间,将整个程序暂停,这对于一些实时性要求比较高的系统是无法接受的。
另外,上面这个标记的过程扫描的是整个堆内存,耗时比较久,最重要的是,它在清除数据的时候,会产生堆内存的碎片。
因此从 Go v1.5 开始,就开始抛弃这种算法,而改用 三色并发标记法。
三色并发标记法
新算法的出现,必然是要解决旧算法存在的最关键问题 ,即STW 的暂停挂起导致的程序卡顿。
它的逻辑就是,准备三种颜色,分别对三种对象进行标记:
- 黑色:检测到有被引用,并且已经遍历完它所有直接引用的对象或者属性
- 白色:还没检测到有引用的对象(检测开始前,所有对象都是白色,检测结束后,没有被引用的对象都是白色,会被清查掉)
- 灰色:检测到有被引用,但是他的属性还没有被遍历完,等遍历完后也会变成黑色
既然 STW 会挂起程序,那是不是可以考虑将其摘除呢?
摘除会带来一个问题就是在标记的时候,程序的运行会不断改变对象的引用路径,影响标记的准确性。
关于不使用 STW 带来的影响可以看一下这篇文章:https://segmentfault.com/a/1190000022030353
总结来说,就是当在标记的时候出现 :一个白色对象被黑色对象引用,同时该白色对象又被某个灰色(或者上级有灰色对象)对象取消引用的情况,就会标记不准确。
因此如果想摘除 STW,那就得规避掉上面这个场景出现。
解决方法是:使用 插入屏障 和 删除屏障
插入屏障
在A对象引用B对象的时候,B对象被标记为灰色。(将B挂在A下游,B必须被标记为灰色)
删除屏障
被删除的对象,如果自身为灰色或者白色,那么被标记为灰色。
延伸阅读
2.12 Go 中哪些动作会触发 runtime 调度?
goroutine 在遇到哪些情况会触发 runtime 的调度器去调度呢?
第一种:系统调用 SysCall
当你在 goroutine 进行一些 sleep 休眠、读取磁盘或者发送网络请求时,其实都会发生系统调用,进入操作系统内核。
而一旦发生系统调用,就会直接触发 runtime 的调度,当前的 P 就会去找其他的 M 进行绑定,并取出 G 开始运行。
第二种:等待锁、通道
此外,在你的代码中,若因为锁或者通道导致代码阻塞了,也会触发调度。
第三种:人工触发
在代码中直接调用 runtime.Gosched 方法,也可以手动触发。
另外说一个小知识,当你执行 fmt.Println 的时候,也会触发调度,这是为什么呢?留给你自己思考咯
2.13 有哪些情况会导致协程泄露?
协程泄露是指,在程序运行过程中,有一些协程由于某些原因,无法正常退出。
协程的运行是需要占用内存和 CPU 时间的,一旦这种协程越来越多,会导致内存无端被浪费,CPU 时间片被占用,程序会越来越卡。
那会导致协程泄露的原因有哪些呢?
其实不用死记硬背,只要有可能导致程序阻塞的,都有可能会导致协程泄露。
那么会让程序阻塞的,无外乎:
- 通道阻塞
- 锁阻塞
- 等待阻塞
1. 通道使用不当
通道和协程是 Go 的两大杀器,配合好了是非常香的,但要是没用好,就会造成协程泄露。
下面是常见的一些通道使用不当导致的协程泄露例子
发送了却没全接收
func main() {
for i := 0; i < 4; i++ {
queryAll()
fmt.Printf("goroutines: %d\n", runtime.NumGoroutine())
}
}
func queryAll() int {
ch := make(chan int)
for i := 0; i < 3; i++ {
go func() { ch <- query() }()
}
return <-ch
}
func query() int {
n := rand.Intn(100)
time.Sleep(time.Duration(n) * time.Millisecond)
return n
}没发送却有人在接收
func main() {
defer func() {
fmt.Println("goroutines: ", runtime.NumGoroutine())
}()
var ch chan struct{}
go func() {
ch <- struct{}{}
}()
time.Sleep(time.Second)
}初始化通道却没分配内存
func main() {
defer func() {
fmt.Println("goroutines: ", runtime.NumGoroutine())
}()
var ch chan int
go func() {
<-ch
}()
time.Sleep(time.Second)
}2. 锁使用不当
加互斥锁后没有解锁
加了互斥锁后,若没有释放,其他 Goroutine 再想获取锁就会阻塞。
因此在加了互斥锁后,可以下意识加个 defer mutex.Unlock(),养成编码习惯
func main() {
total := 0
defer func() {
time.Sleep(time.Second)
fmt.Println("total: ", total)
fmt.Println("goroutines: ", runtime.NumGoroutine())
}()
var mutex sync.Mutex
for i := 0; i < 10; i++ {
go func() {
mutex.Lock()
// 正常加锁后,可以下意识加个 defer mutex.Unlock()
total += 1
}()
}
}同步锁使用不当
如下例子中,wg.Add 的数量与 wg.Done 的数量不一致,就会导致 wg.Wait 阻塞。
func handle(v int) {
var wg sync.WaitGroup
wg.Add(5)
for i := 0; i < v; i++ {
wg.Done()
}
wg.Wait()
}
func main() {
defer func() {
fmt.Println("goroutines: ", runtime.NumGoroutine())
}()
go handle(3)
time.Sleep(time.Second)
}3. 慢等待未响应
在下面这个例子中,发送一个 http 请求的时候,如果网络非常的卡,导致这个请求一直没有收到响应,那么就会一直进行 for 循环,不断创建新的协程。
func main() {
for {
go func() {
_, err := http.Get("https://www.xxx.com/")
if err != nil {
fmt.Printf("http.Get err: %v\n", err)
}
// do something...
}()
time.Sleep(time.Second * 1)
fmt.Println("goroutines: ", runtime.NumGoroutine())
}
}